Usage Control
In this part you will learn how to control data flows within the Trusted Connector using LUCON policies.
Introduction to LUCON
LUCON (Logic based Usage Control) is a policy language for controlling data flows between endpoints. The Trusted Connector uses Apache Camel to route messages between services (such as MQTT, REST, or OPC-UA endpoints). The ways how messages may be processed and passed around between services is controlled by LUCON, a simple policy language for message labeling and taint tracking.
The LUCON policy language comes with an Eclipse plugin for syntax highlighting, code completion and compilation into a format that is understood by the policy decision point within the Connector. Thus the typical workflow is as follows:
- Write a LUCON policy in Eclipse (Install Eclipse Plugin). As you type, Eclipse compiles the policy into a .pl (Prolog) file in the
compiled-policiesfolder. - Load the compiled policy into the Connector & activate it
Data Flow Rules
Consider the following example rules.
Personal data must be anonymized before leaving the Connector
flow_rule {
id anonymized // Rule id
description "Do not leak personal or internal data"
when publicEndpoint // Target identifier
receives { label(personal) or label(internal) } // Received message labels
decide drop // Drop message
}
In this example, a rule anonymized declares that if any service matching the publicEndpoint description receives a message that contains a label personal or a label internal, the message has to be dropped.
Data must be deleted after 30 days
flow_rule {
id deleteAfterOneMonth // Rule id
description "Deletes all hadoop data after 30 days"
when hadoopCluster // Target identifier
receives * // Received message labels
decide allow // Allow if requirements fulfilled
require delete_after_days(X), X<30 // Obligation
otherwise drop // Alternative
}
In this example, a rule deleteAfterOneMonth declares that all messages (indicated by receives *) sent into a service matching the hadoopCluster description must be deleted after 30 days. If the service does not support deletion, the message must be dropped.
Service Descriptions
Flow rules refer to service descriptions. A service description declares a set of services to which rule applies. It consists of the following elements:
id(required) A unique identifier to which anyflow_rulemay refer to.description(optional) A string describing the purpose of the rule. It is just for information and has no effect on the policy.endpoint(required) A regular expression describing the endpoints matched by this servicecapabilities(optional) A description of actions, the service can execute. If a rule requires actions which are not supported, theotherwiseclause is appliedproperties(optional) Further descriptive properties of the serviceremoves_label(optional) Comma-separated list of labels which will be removed from outgoing messages of the servicecreates_label(optional) Comma-separated list of label which will be added to outgoing messages of the service
The first example defines a service that can blind the fields “surname” and “name” and thus removes the label personal. Messages that pass this service, will not be dropped by rule anonymized.
service {
id anonymizerService
// Defines the Camel endpoints for which this service description applies, using a specific endpoint address.
endpoint 'http://localhost/anonymizer'
// Capabilities can be required by a flow_rule. If not required, nothing will happen
capabilities
anonymization: personal_data([surname,name])
// Properties describe the service's behavior.
removes_label personal
}
The second example, matching rule deleteAfterOneMonth defines a set of database services that are able to run a delete_after_days action and add a label persisted to messages.
service {
id hadoopCluster
// Defines the Camel endpoints for which this service description applies, using a regular expression.
// Everything starting with hdfs:// or sql:// applies.
endpoint '^(hdfs|sql)://.+'
// Capabilities can be required by a flow_rule. If not required, nothing will happen
capabilities
deletion: delete_after_days(X)
creates_label persisted
}
Install Eclipse Plugin
Download any Eclipse installation from the Eclipse web site. We recommend using the Eclipse Installer.
In Eclipse, click on Help -> Install New Software
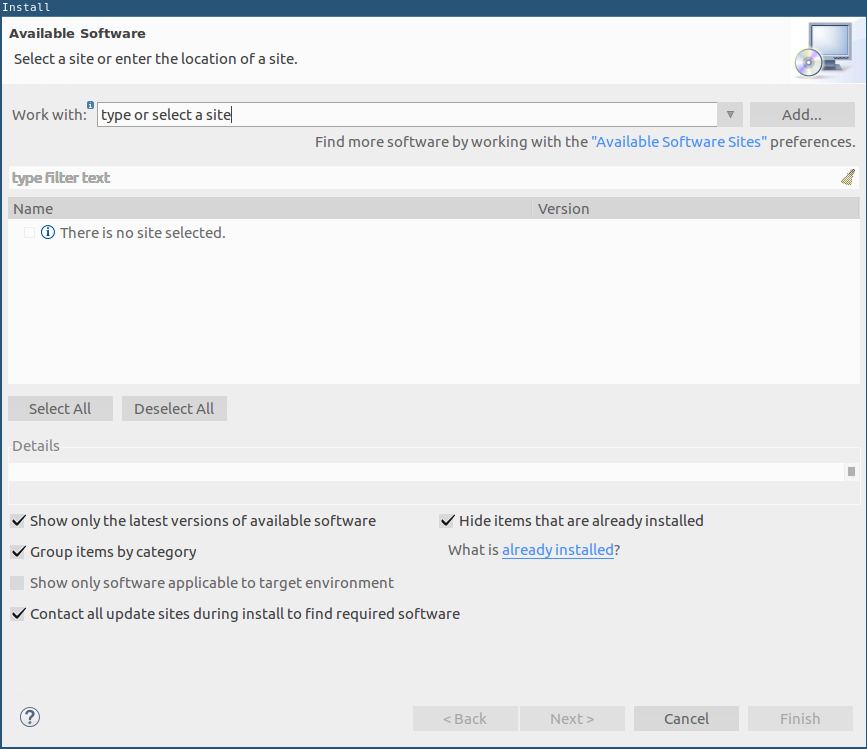
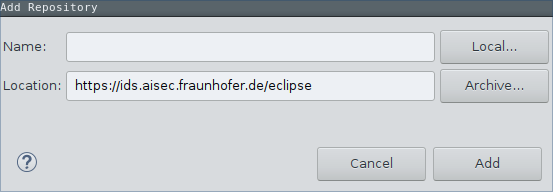
Click on Add… and enter the LUCON update site URL: https://ids.aisec.fraunhofer.de/eclipse.
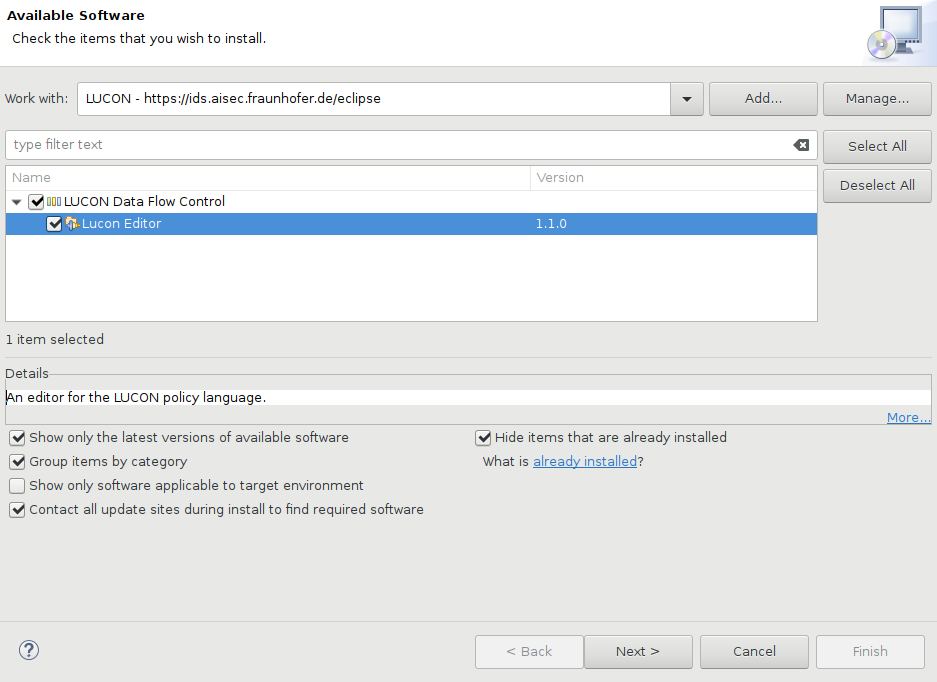
Select and install the LUCON Policy Editor feature.
Write a Policy
In Eclipse, create a new project and open a new file demo.lucon. By default, all messages will be blocked, so we create a policy that allows publication of a message over an HTTP(S)/WebSocket endpoint if the message is marked as public.
As only calls to a SanitizerBean will add the public label, the policy guarantees that all messages will flow through that bean which will remove personal data.
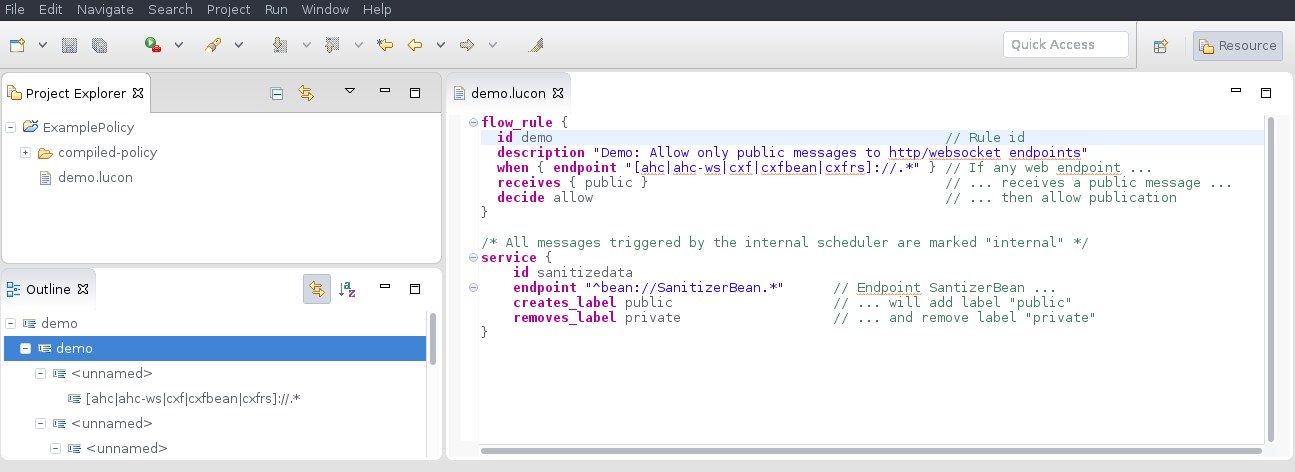
As you type, Eclipse will create a file demo.pl in the compiled-policies folder. This file contains Prolog predicates representing the compiled policy. It is not necessary to understand or edit those generated files.